复习知识
-
date_range 19/03/2018 infosortNote
在Rockchip这两年,感觉Embedded的东西都被我搞的差不多了,特没意思。。。(逃
所以最近跳槽换了个工作,主要为自动驾驶平台写应用程序,之所以转到这个方向,是因为觉得之前在底层(Kernel和硬件驱动),GNU/Linux系统的相关经验能在这里起到很大帮助。
新的工作是开发类似ROS一类的应用。考虑到自己自从大学毕业后,很久没有系统的写过C++,甚至OOP编程也没怎么写,所以决定在这个离职到入职的一个月里,再复习下上学时候的软工知识。
《深入理解C++11》
右值
所有的值属于左值,将亡值(返回&&引用还有move),纯右值(1,true)。 std::move 强制左值转右值。const会使右值变左值,要谨慎使用。
注意完美转发。

拷贝构造
HasPtrMem(HasPtrMem &p);
移动语义
HasPtrMem(HasPtrMem &&p);
移动构造在临时变量的拷贝时候触发。

others
constexpr
相比const,constexpr可以让赋值在编译时被确定,从而能把该变量保存的ROM里。以前上学的时候用C++写OS的时候,有用到这个,不过写应用软件应该不会接触这个了。
noexcept
noexcept修饰的函数不会抛出异常,可以阻止异常的传播与扩散。
final/override
final可以使派生类不可覆盖他修饰的虚函数。
override则是使派生类必须虚函数,防止基类的虚函数发生了变化。
explicit
可以阻止隐式的类型转换。
initializer_list
这个还可以防止类型收窄

多继承
多继承是指一个子类继承多个父类。多继承对父类的个数没有限制,继承方式可以是公共继承(用public继承时,派生类内部可以访问基类中public和protected成员)、保护继承(类外也不能通过派生类的对象访问基类的成员)和私有继承(类外也不能通过派生类的对象访问基类的成员, public,protected变成private)。
由输出结果可以看出,在多继承中,任何父类的指针都可以指向子类的对象,在实例化子类时,先根据继承的顺序依次调用父类的构造函数,然后再调用该子类自己的构造函数;
虚函数表


《More Effective+C++》
指针与引用
总的来说,在以下情况下你应该使用指针,一是你考虑到存在不指向任何对象的可能(在 这种情况下,你能够设置指针为空),二是你需要能够在不同的时刻指向不同的对象(在这 种情况下,你能改变指针的指向)。如果总是指向一个对象并且一旦指向一个对象后就不会 改变指向,那么你应该使用引用。
《深入理解linux内核》
和工作无关。。。只是以后Kernel Level的工作估计很少做了,再看看,巩固下知识。
进程
task_struct 进程描述符, thread_info指向task_struct,放在栈的最下面。

parent的pid是其他的tgid,同样一个tgid的算一个进程组。
线程一般是进程允许共享页表,打开文件表,信号处理。
Linux内核在创建进程的时候,是写时复制,只有写新物理页的时候,才会拷贝一个新的。(内核只为新生成的子进程创建虚拟空间结构,它们来复制于父进程的虚拟究竟结构,但是不为这些段分配物理内存,它们共享父进程的物理空间,当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间)
vfork不会复制页表项,因此父进程必须等子退出才行,vfork的程序一般会另外调用exec,创建自己的页表,不需要复制主的。
进程僵死,是因为需要通知父进程,不能马上就删除进程描述符这些资源
中断
软中断和tasklet是中断上下文,但是是中断下半部。tasklet是一种软中断,一般用在IO上。

fault可以修复,trap没有影响,一般只是为了debug,abort会终止进程。中断描述符存放入口。
在中断禁止过程中丢失的中断(比如说do_IRQ, 在do_IRQ被调用时,处理器已经屏蔽了对外部中断的响应)(为了支持中断的嵌套执行,Linux内核在进入中断服务程序之前会将硬中断开启,运行完中断服务程序之后再将硬中断关闭,在这期间硬件中断是可以被抢占的),在irq_enable的时候,会通过内核代码检查一次,手动触发。
linux支持中断嵌套,一个中断可以抢占其他中断和异常,不过异常不能抢占中断,一般来说内核里的异常就缺页,中断处理函数不会触发缺页。
IRQF_ONESHOT保护,只有中断下半部分threaded_handler执行完才行。(这是因为在旧的中断处理机制中,top half是不可重入的,强制线程化之后,强制设定IRQF_ONESHOT可以保证threaded handler是不会重入的)(在那些被强制线程化的中断线程中,disable bottom half的处理。这是因为在旧的中断处理机制中,botton half是不可能抢占top half的执行,强制线程化之后,应该保持这一点)
内核同步
一个tasklet,softirq不会在不同CPU上执行,可以减少同步问题。
每CPU变量都需要禁止抢占才能访问,避免其他CPU访问到了。
内存屏障既用于多处理器系统(MP),也用于单处理器系统(UP),api前面带smp,都是用于多处理器的。
http://www.wowotech.net/kernel_synchronization/memory-barrier.html
spin_lock会禁止抢占,但是只有在lock住后才禁止抢占,如果是在忙等,还是会被抢占的。 rw_lock读写自旋锁。 seqlock顺序锁,类似读写自旋锁,但是允许读的时候写。 这几个锁的实现都是基于原子变量的加减实现的。
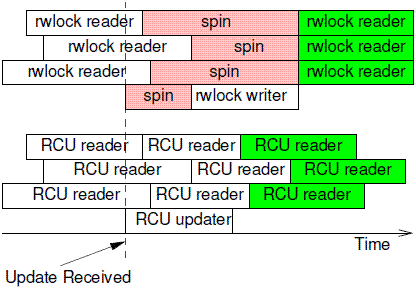
RCU是为了保护被多个CPU读的数据而设计的结构,允许多个读者和写者(rwlock只允许一个写),另外rcu不使用ALL CPU的变量,效率高。
读者不需要获得任何锁就可以访问它,但写者在访问它时首先拷贝一个副本,然后对副本进行修改,最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据,当然也可以直接用rcu_assign_pointer和synchronize_rcu赋值。RCU允许多个读者同时访问被保护的数据,也允许多个读者在有写者时访问被保护的数据。
rcu_read_lock会关抢占,不能在临界区睡眠,因为写者执行完毕后需要调用回调函数,这样就被阻塞住了。
http://www.wowotech.net/kernel_synchronization/rcu_fundamentals.html
注意rcu的指针替代是原子语句,reclaimer不管同步

rcu和spin lock的对比:由此可见,RCU的并发性能要好于rwlock,而且rcu比基于counter(需要访问存储器件)的锁(例如spin lock,rwlock)的机制开销会更小。
定时
clocksource(clocksource不能被编程,没有产生事件的能力,它主要被用于timekeeper来实现对真实时间进行精确的统计):http://www.wowotech.net/timer_subsystem/clocksource.html
clockevent(触发中断的) : http://www.wowotech.net/timer_subsystem/clock-event.html
timekeeper: http://blog.csdn.net/DroidPhone/article/details/7989566
arm-timer(注意armtimer一般依赖一个system counter做源,arm-timer注册是clocksource设备,rk-timer是clockevent设备): http://www.wowotech.net/timer_subsystem/armgeneraltimer.html

jiffies记录系统节拍。
动态定时器通过软件实现,没有限制。
调度
linux调度基于分时,cpu时间被分成slice。
《Head First设计模式》
面向对象的核心特性包括封装、继承和多态
封装从字面上来理解就是包装的意思,专业点就是信息隐藏,是指利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体,数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外接口使之与外部发生联系。
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类
所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
面向对象编程一定程度上是借鉴现实世界中物体与物体之间的联系,将有特定功能或者说有内在联系的代码抽象成一个类,使代码更容易被理解,更容易被重用。
设计模式的目的:抵御变化,达成复用。
观察者模式
一个目标物件管理所有相依于它的观察者物件,并且在它本身的状态改变时主动发出通知。他定义了一对多的关系。

例子:weather和气象站。
工厂模式
在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
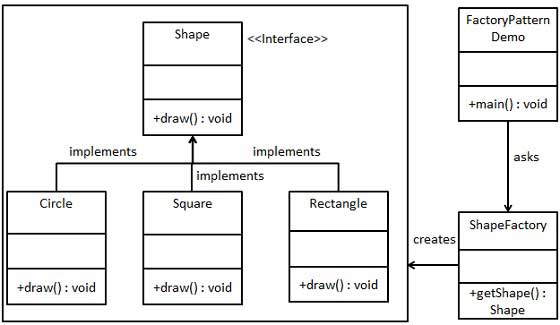
优点: 1、一个调用者想创建一个对象,只要知道其名称就可以了。 2、扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以(不同口味pizza)。 3、屏蔽产品的具体实现,调用者只关心产品的接口(pizza -> new prepare back put -> create)。
缺点:每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖。这并不是什么好事。
抽象工厂:用于一个产品族

策略模式
策略模式定义了一系列的算法,并将每一个算法封装起来,而且使他们可以相互替换,让算法独立于使用它的客户而独立变化。

装饰者模式
装饰着模式的含义:动态的给一个对象添加一些额外的职责,就增加功能来说,装饰模式比生成子类更为灵活。

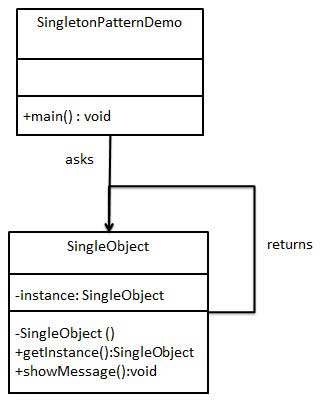
单例模式
保证一个类仅有一个实例,并提供一个访问它的全局访问点。
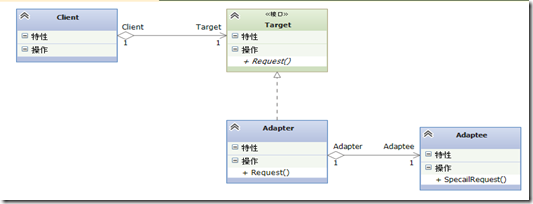
适配器模式
适配器模式定义:将一个类的接口,转化成客户期望的另一个接口,适配器让原本接口不兼容的类可以合作无间
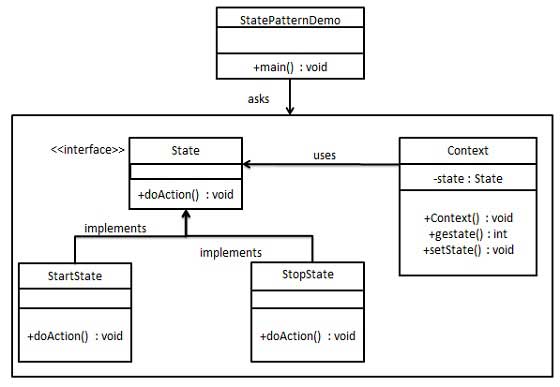
状态模式
允许对象在内部状态发生改变时改变它的行为,对象看起来好像修改了它的类
其他
命令模式(command和订单),模板方法模式(骨架,比如说sort对应qsort),迭代器与组合模式(指针-》不同的集合类型所造成的遍历),代理模式(通过代理对象访问目标对象,可以增加实现),复合模式
《算法导论》
这个和工作无关,只是为了以后再跳槽的可能要用。
面Embedded的工作的时候,基本上其实也不会涉及算法,最多写个简单的软件过程而已。
但是面一般软开的时候,因为缺少相关经验,因为都会让我做题。。。
因此,我也错过了Nvidia和百度的机会。
《深度学习》
长长知识。
面试常见问题
mutex怎么多进程
Posix信号量就可以,创建命名锁,就可以在不同进程里实现。匿名锁的主要问题是怎么找到。
pthread_mutexattr_setpshared可以使pthread的锁共享。
likely性能提升
likely实质是把容易执行的条件放到CPU流水线会预处理的地方,这样如果条件满足,就直接使用预处理的结果,不然处理器会放弃整个流水线。
copy_from_user?
先用access_ok判断地址
然后具体的__copy_from_user函数负责拷贝。
为什么专门用函数拷贝呢?
因为用户进程传来的地址是虚拟地址,这段虚拟地址可能还未真正分配对应的物理地址。
对于用户进程访问虚拟地址,如果还未分配物理地址,就会触发内核缺页异常,
接着内核会负责分配物理地址,并修改映射页表。这个过程对于用户进程是完全透明的。
但是在内核空间发生缺页时,必须显式处理,否则会导致内核oops。
delete实现原理,删错地址了怎么办
见此图片

面向对象五个基本原则
- 单一职责原则(SRP): 一个类应该仅有一个引起它变化的原因(最简单,最容易理解却最不容易做到的一个设计原则)
- 开放封闭原则(OCP): 既开放又封闭,对扩展是开放的,对更改是封闭的!; 扩展即扩展现行的模块,当我们软件的实际应用发生改变时,出现新的需求,就需要我们对模块进行扩展,使其能够满足新的需求!
- 里氏替换原则(LSP): 子类可以替换父类并且出现在父类能够出现的任何地方!; 这个原则也是在贯彻GOF倡导的面向接口编程!在这个原则中父类应尽可能使用接口或者抽象类来实现!
- 依赖倒置原则(DIP): 传统的结构化编程中,最上层的模块通常都要依赖下面的子模块来实现,也称为高层依赖低层!让高层模块不要依赖低层模块,所以称之为依赖倒置原则!高层应该依赖的是抽象。
- 接口隔离原则(ISP): 这个原则的意思是:使用多个专门的接口比使用单个接口要好的多!这是接口隔离原则的核心定义,接口要尽量小,不要出现臃肿的接口,但是小也是有限度的,不能违背单一职责原则。具体到接口隔离原则就是要求在接口中尽量减少公布public方法
无锁化
当今比较流行的 Non-blocking Synchronization 实现方案有三种:
- Wait-free 是指任意线程的任何操作都可以在有限步之内结束,而不用关心其它线程的执行速度。
- Lock-Free 是指能够确保执行它的所有线程中至少有一个能够继续往下执行。
- Obstruction-free 是指在任何时间点,一个孤立运行线程的每一个操作可以在有限步之内结束。只要没有竞争,线程就可以持续运行。一旦共享数据被修改,Obstruction-free 要求中止已经完成的部分操作,并进行回滚。 所有 Lock-Free 的算法都是 Obstruction-free 的。
二叉树中两个节点的最近公共祖先节点
从树的根节点开始和两个节点作比较,如果当前节点的值比两个节点的值都大,则这两个节点的最近公共祖先节点一定在该节点的左子树中,则下一步遍历当前节点的左子树;
如果当前节点的值比两个节点的值都小,则这两个节点的最近公共祖先节点一定在该节点的右子树中,下一步遍历当前节点的右子树;这样直到找到第一个值是两个输入节点之间的值的节点,该节点就是两个节点的最近公共祖先节点。
伙伴算法
Buddy(伙伴的定义): 这里给出伙伴的概念,满足以下三个条件的称为伙伴:
1)两个块大小相同;
2)两个块地址连续;
3)两个块必须是同一个大块中分离出来的;
Buddy算法的分配原理: 假如系统需要4(22)个页面大小的内存块,该算法就到free_area[2]中查找,如果链表中有空闲块,就直接从中摘下并分配出去。如果没有,算法将顺着数组向上查找free_area[3],如果free_area[3]中有空闲块,则将其从链表中摘下,分成等大小的两部分,前四个页面作为一个块插入free_area[2],后4个页面分配出去,free_area[3]中也没有,就再向上查找,如果free_area[4]中有,就将这16(2222)个页面等分成两份,前一半挂如free_area[3]的链表头部,后一半的8个页等分成两等分,前一半挂free_area[2] 的链表中,后一半分配出去。假如free_area[4]也没有,则重复上面的过程,知道到达free_area数组的最后,如果还没有则放弃分配。
Buddy算法的释放原理: 内存的释放是分配的逆过程,也可以看作是伙伴的合并过程。当释放一个块时,先在其对应的链表中考查是否有伙伴存在,如果没有伙伴块,就直接把要释放的块挂入链表头;如果有,则从链表中摘下伙伴,合并成一个大块,然后继续考察合并后的块在更大一级链表中是否有伙伴存在,直到不能合并或者已经合并到了最大的块(222222222个页面)。
可以解决内存碎片问题。
3sum
然后对于3 Sum问题,解决方法就是最外层遍历一遍,等于选出一个数, 之后的数组中转化为找和为target-nums[i]的2SUM问题。 因为此时排序复杂度在3SUM问题中已经不占据主要复杂度了,所以直接排序,然后设置两个指针,一个指向数组开头,一个指向数组结尾,从两边往中间走。直到扫到满足题意的为止或者两个指针相遇为止。