ARM Midgard GPU
-
date_range 30/12/2017 infosortEmbedded and Linux
最近突然对arm mali gpu的硬件结构蛮有兴趣,所以找了篇arm上的文章看了下。
看得就是这篇arm的文章,我来尝试简单复述一下这个文章里的内容。
The CPU-GPU rendering pipeline
API看起来是同步的,实则硬件大多是异步执行,包括gldraw和swapbuffer。
博客里解释这是因为性能的关系。
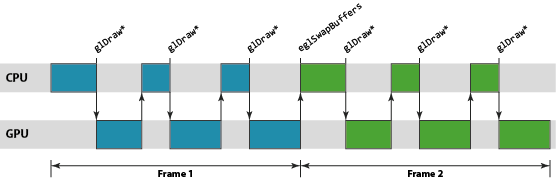
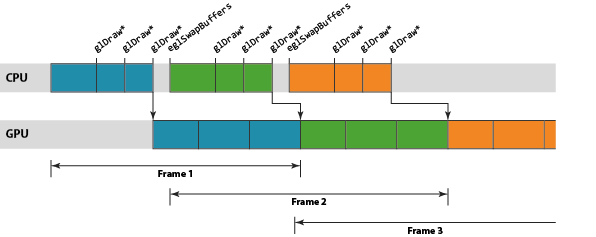
在mali上vertex和fragment是分开的模块,所以这两个也可以并行。

Throttling
就是说如何控制GPU的负载,因为在异步下,负载大意味着延时大。
“This throttling mechanism is normally provided by the host windowing system, rather than by the graphics driver itself.” 所以这是由操作系统决定的。
Tile-based rendering
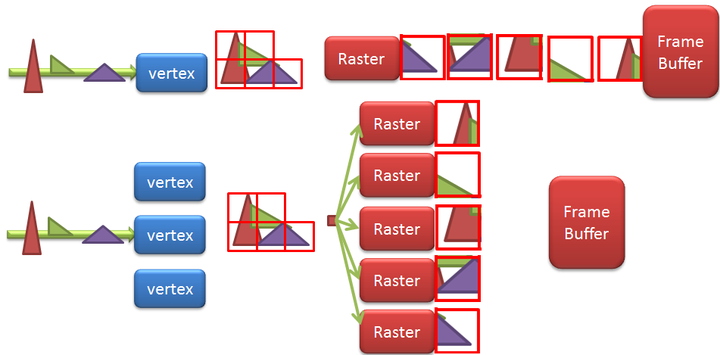
传统的rendering方式:
“In a traditional mains-powered desktop GPU architecture — commonly called an immediate mode architecture — the fragment shaders are executed on each primitive, in each draw call, in sequence. Each primitive is rendered to completion before starting the next one”
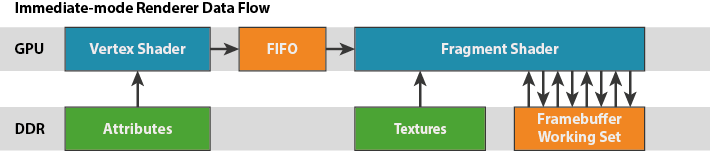
这样的缺点就是每次fragment shaded操作都要占用ddr带宽,
mali的Tile-based rendering方式:
“ It first executes all of the geometry processing, and then executes all of the fragment processing. During the geometry processing stage, Mali GPUs break up the screen into small 16x16 pixel tiles and construct a list of which rendering primitives are present in each tile. When the GPU fragment shading step runs, each shader core processes one 16x16 pixel tile at a time, rendering it to completion before starting the next one.”
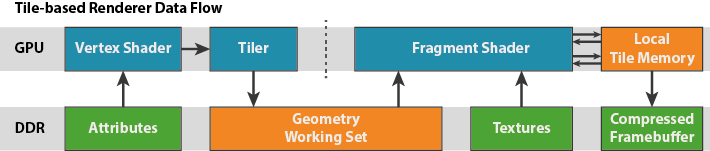 如何在如此小的一块tile缓存中渲染出高分辨率的图像?解决方案就是将OPENGL的帧缓存切割成16x16的小块(这就是tile-based渲染的命名由来),然后一次就渲染一块。对于每一块tile: 将有用的几何体提交进去,当渲染完成时,将tile的数据拷贝回主内存。这样,带宽的消耗就只来自于写回主内存了,那是一个较小的消耗:没有d/s,没有重绘的像素,没有多采样缓存。同时,消耗极高的深度/模板测试和颜色混合完全的在计算芯片上就完成了。
如何在如此小的一块tile缓存中渲染出高分辨率的图像?解决方案就是将OPENGL的帧缓存切割成16x16的小块(这就是tile-based渲染的命名由来),然后一次就渲染一块。对于每一块tile: 将有用的几何体提交进去,当渲染完成时,将tile的数据拷贝回主内存。这样,带宽的消耗就只来自于写回主内存了,那是一个较小的消耗:没有d/s,没有重绘的像素,没有多采样缓存。同时,消耗极高的深度/模板测试和颜色混合完全的在计算芯片上就完成了。
优点:It is clear from the list above that tile-based rendering carries a number of advantages, in particular giving very significant reductions in the bandwidth and power associated with framebuffer data, as well as being able to provide low-cost anti-aliasing
缺点:需要获取framebuffer结果的时候,会更慢。所以最好glBindFramebuffer只用一次。 另外这种渲染方式还会带来延迟。因为要整个场景的primitive都收到后才能开始Raster
取出framedata: Most content has a depth and stencil buffer, but doesn’t need to keep their contents once the frame rendering has finished. If developers tell the Mali drivers that depth and stencil buffers do not need to be preserved2 — ideally via a call to glDiscardFramebufferEXT (OpenGL ES 2.0) or glInvalidateFramebuffer (OpenGL ES 3.0), although it can be inferred by the drivers in some cases — then the depth and stencil content of tile is never written back to main memory at all. Another big bandwidth and power saving!
其他阅读
https://www.zhihu.com/question/49141824?from=profile_question_card https://www.cnblogs.com/gameknife/p/3515714.html
Shader core architecture
“unified shader core architecture, meaning that only a single class of shader core which is capable of executing all types of shader programs and compute kernels exists in the design”
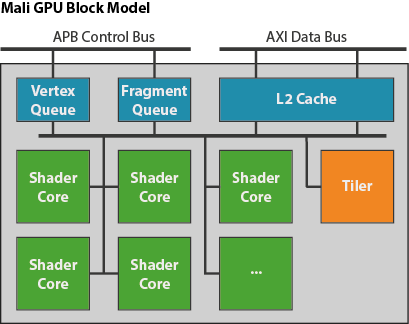 “The graphics work for the GPU is queued in a pair of queues, one for vertex/tiling workloads and one for fragment workloads,so vertex processing and fragment processing for different render targets can be running in parallel.”
“The graphics work for the GPU is queued in a pair of queues, one for vertex/tiling workloads and one for fragment workloads,so vertex processing and fragment processing for different render targets can be running in parallel.”
“The workload for a single render target is broken into smaller pieces and distributed across all of the shader cores in the GPU, or in the case of tiling workloads (see the second blog in this series for an overview of tiling) a fixed function tiling unit”
“The shader cores in the system share a level 2 cache to improve performance, and to reduce memory bandwidth caused by repeated data fetches”
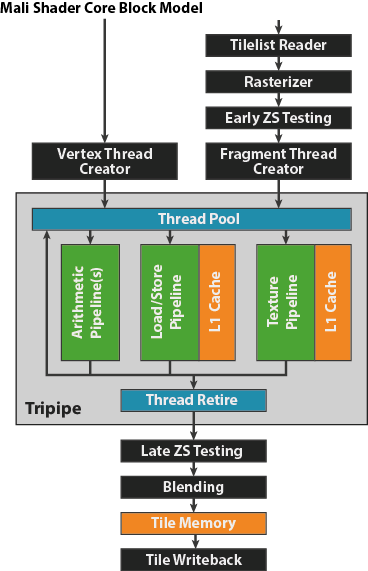 “Unlike a traditional CPU architecture, where you will typically only have a single thread of execution at a time on a single core, the tripipe is a massively multi-threaded processing engine”
“Unlike a traditional CPU architecture, where you will typically only have a single thread of execution at a time on a single core, the tripipe is a massively multi-threaded processing engine”
OpenCL
“Both of these types of work behave almost identically to vertex threads - you can view running a vertex shader over an array of vertices as a 1-dimensional compute problem.”
The Bifrost Shader Core
新的the Bifrost family GPU的shader core, 区别于midgard的shader core,没什么好看的。。。
文章链接
https://community.arm.com/graphics/b/blog/
https://community.arm.com/graphics/b/blog/posts/the-mali-gpu-an-abstract-machine-part-1—frame-pipelining
https://community.arm.com/graphics/b/blog/posts/the-mali-gpu-an-abstract-machine-part-3—the-midgard-shader-core
https://community.arm.com/graphics/b/blog/posts/the-mali-gpu-an-abstract-machine-part-2—tile-based-rendering
https://community.arm.com/graphics/b/blog/posts/the-mali-gpu-an-abstract-machine-part-4—the-bifrost-shader-core