ROS编程-ROS程序编写的一些Tips
-
date_range 20/03/2019 info
接触了快一年的ROS, 这段时间个人而言, 似乎完全没在日常的编程中对线程/IPC有所考虑.
这说明ROS是一个很易用的框架, 在编程上了屏蔽了很多系统知识, 可以更加专注于逻辑/算法等.
但是从程序员的角度, 其实还是蛮不安的, 需要了解其背后的机制.
1. 背景
ROS就不再介绍了, 网上有非常多的文档, 我们主要关注下ROS内部的一些行为.
下图是我之前画的ROS内部线程视角的时序图, 看看能不能帮助理解:
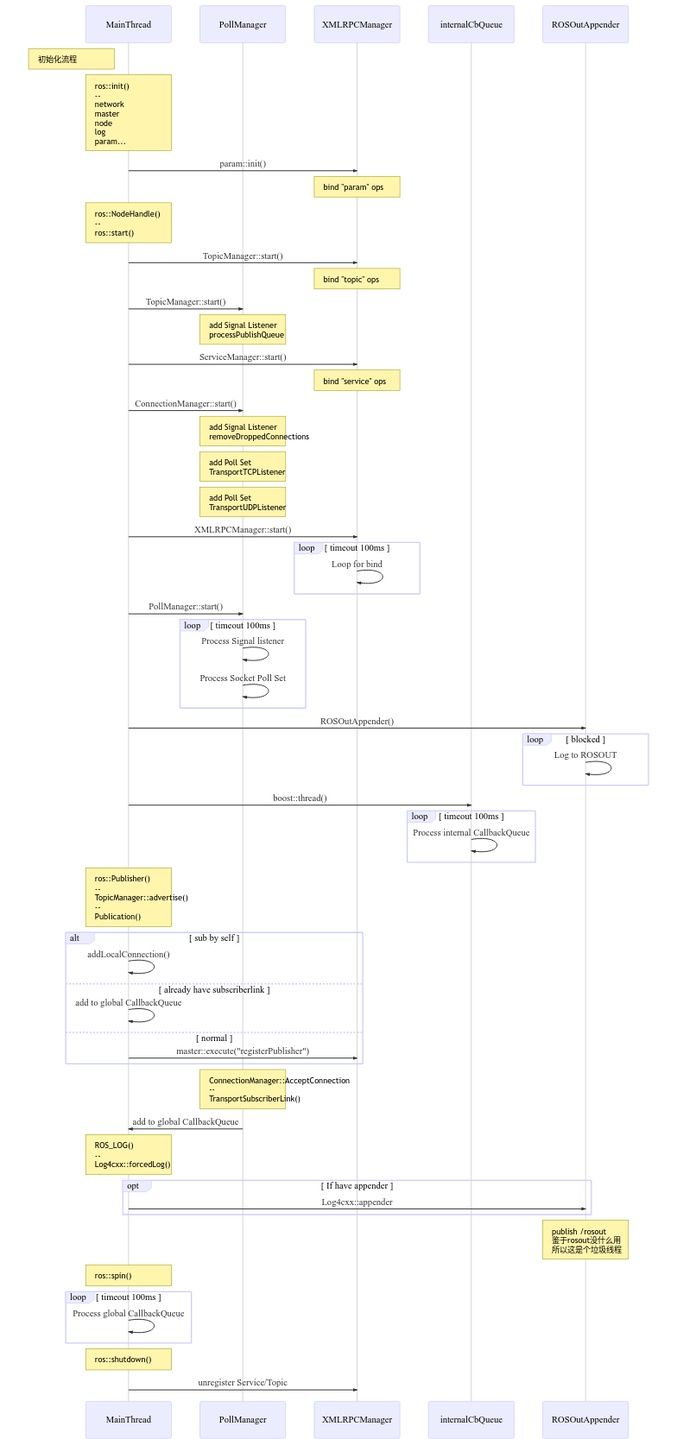
一个ROS节点起来后, 主要是有5个线程:
- main
- main函数运行的线程
- pollmanager
- io运行的线程, 主要是收发topic, 然后把数据queue后待callback消费
- xmlrpcmanager
- 处理service连接的线程
- internalcallbackqueue
- 调用内部callback的线程
- rosoutappender
- rosout线程
其他还有asyncspinner/multithreadspinner线程可以创建, 其执行逻辑可以理解为:
thread_func() {
if (特殊callbackqueue)
call 特殊callbackqueue
else
call 全局callbackqueue
}
从topic收发的解读理解:
- pollmanager部分:
- socket poll + recv
- 把收到的数据放到内部的data queue, 如果data queue满则丢弃
- main或者asyncspinner部分:
- ros::spin()
- call global_callbackqueue
- 从data queue取出数据, 调用topic的callback
- ros::spin()
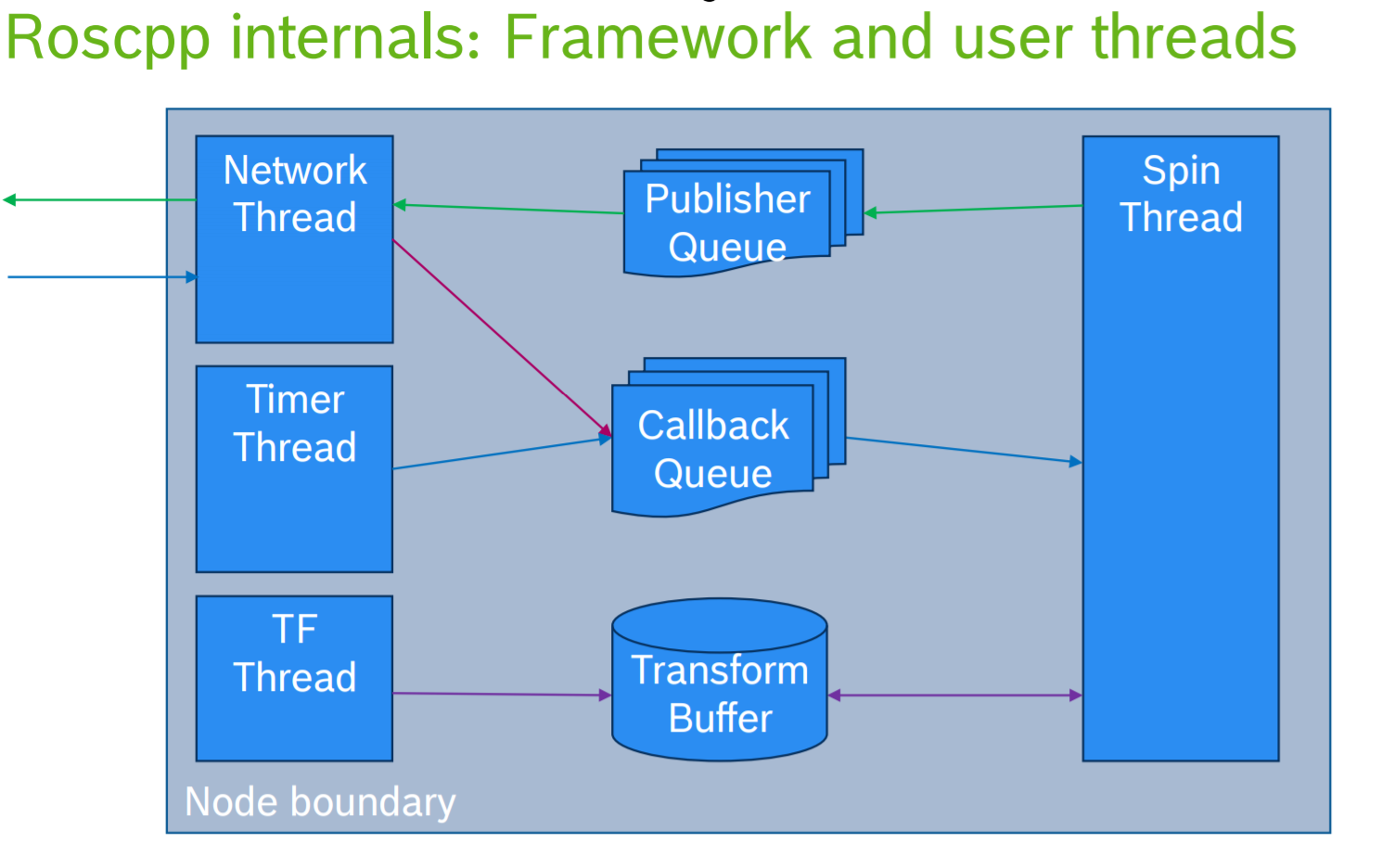
2. Tips
理解完背景, 下面就可以分析一些常见的问题
2.1. spinOnce使用
while ( ros::ok()) {
ros::spinOnce();
Proc();
sleep(50ms);
}
如上写法是很常见的ros程序写法.
ros::spinOnce()会调用topic allback, 处理完50ms内queue里保存的topic数据.
这种写法会出现几个现象:
spinOnce50ms调用一次, topic消费慢, 丢包严重spinOnce耗时大/波动, 导致Proc的延迟大/波动
合适的写法如下:
auto timer_func = [](void) {
Proc();
}
create_timer(timer_func);
ros::spin();
在timer_func外的空闲时间, 程序会处理topic callback, 从而减少丢包和Proc的延迟波动
2.2. AsyncSpinner/MultiThreadedSpinner使用
void callback1() {
data = 1;
}
void callback2() {
cout << data;
}
void main() {
......
ros::AsyncSpinner spinner(4); // Use 4 threads
spinner.start();
ros::waitForShutdown();
}
就是没有锁保护的问题….
别笑, 搜一下, 肯定有用错的.
2.3. callback阻塞
默认情况下, 可以认为ros上所有的callback, 包括topic/timer, 全是顺序执行的. 有一个地方出现阻塞/延迟, 就会引起整个节点的卡死/延迟.
void callback_a() {
复杂逻辑;
}
void callback_b() {
复杂逻辑;
}
void callback_c() {
复杂逻辑;
}
在上面的程序中, 很容易出现一种情况, 就是程序花费了大量时间在callback_a上, 而程序核心可能是callback_c, 但因为顺序执行的关系, 得不到足够的资源.
合适的做法应该是:
void callback_a() {
保存数据;
}
void callback_b() {
保存数据;
}
void callback_c() {
复杂逻辑;
}
这样牺牲掉a的一些数据, 换来c的稳定执行.
2.4. topic频率过高
jacob@ubuntu:~$ rostopic hz /tf
subscribed to [/tf]
average rate: 957.470
min: 0.000s max: 0.010s std dev: 0.00207s window: 939
jacob@ubuntu:~$ rostopic bw /tf
subscribed to [/tf]
average: 89.24KB/s
mean: 0.10KB min: 0.09KB max: 0.10KB window: 100
如上一个topic, 从带宽上看不高, 所以我们很容易认定这个topic”无害”. 但从ros内部行为理解, 会发现这种高频的topic会无端消耗非常多的资源.
以十收一发为例:
- 发送者:
- 1w的Socket Send Per Second
- 接受者:
- 1k的Socket Read Per Second
- 1k的Callback Call Per Second(如果queue长度够, 没有丢包)
对发送者, 可能光是发送开销就占到单核10-20%.
对接受者来说, 会浪费执行时间在pollmanager/spinner 高频topic处理上.
2.5. 订阅过多topic
在没有架构梳理+基于ros编程的情况下, 我们很容易写出订阅数超过10个topic的节点.
按照之前解释的内部逻辑, 所有topic的socket都在pollmanager, callback都在global callbackqueue处理, topic间不区分重要性, 共享处理资源.
这种情况下, 如果出现上述的高频topic, 那有可能影响到其他关键topic, 导致丢包和延迟.
合适的解法:
- 架构梳理
- Topic合并, 减少Topic数量/频率
- 不订阅非必要的Topic
- 使用AsyncSpinner
- 要注意有可能增加程序复杂度, 不建议使用
- 合理设置queue_size, 对不重要的topic进行丢包(建议)
- topic callback不做复杂逻辑
- ros层优化, 增加qos特性, 区分topic重要性
2.6. 大topic传输
一个1080p/60fps的RGB图像topic, 其带宽是300MB/s.
如果是基于rostopic socket来传输, 那么因为序列化反序列化的存在, 带宽还要*3.
基础背景:
在一般的x86架构下, 单线程memcpy的速度大概在2000MB+/S.
在risc(arm)架构下, 这个值会低的多, 单线程memcpy的速度大概在5-600MB+/S.
合适的解法:
- 架构梳理足够强势的情况下, 可以:
- 全链路的图像/lidar使用share dmabuffer轮转, 这样不管是CPU/GPU, 都可以高效使用
- 或者在驱动侧拷贝共享内存轮转
- ros传输优化
2.7. 订阅topic的queue太大
很多人喜欢随意给queue设个100.
这种情况下, 就会出现一次SpinOnce消费100个数据的情况!
所以不要随意给不重要的topic设置大queue.
2.7. service 长连接/短连接
ros::ServiceClient client = nh.serviceClient<my_package::Foo>("my_service_name", true);
对与频繁调用的ros service来说, 后面的true很重要, 可以建立起长连接.
如果不使用长连接, 每次ros service调用都会消耗掉毫秒级的开销来重新建立连接.
3. 其他
虽然有这个那个的问题, 但是最好不要为了解决这些问题, 用上酷炫的解法.
ros这样做的本意就是不让开发者天马行空.
对于项目而言, 合适的做法应该是整理出系统性的解决方法然后统一处理.