无人车安全-容错设计探讨
-
date_range infosort
(YY, 请勿参考)

1. 背景
最近看了一个ppt, Fault-Tolerance in Avionics Systems.
ppt比较易懂的解释了航空系统中的容错机制, 感觉有些意思.
之前也看过相关片段, 像SpaceX是在火箭和飞船的控制上粗放的使用了n+个Linux x86电脑, 主要通过额外的容错机制来做到robust.
这里也跟着遐想, 如何将自动驾驶车辆按照航天器标准设计.
下面是对ppt的截取.
1.1. 介绍
- Fault Tolerance: 指错误检测, 损坏评估, 故障隔离以及从错误中恢复的能力.
- Fault:可能导致系统或功能失效的异常条件, 可译为“故障”.
- Error:计算、观察或测量值或条件, 与真实、规定或理论上正确的值或条件之间的差异, 可译为“错误”.
- Failure:当一个系统不能执行所要求的功能时, 即为Failure, 可译为“失效”.
现代Fault Tolerance主要关注两种Fault, Byzantine Faults 和 Common Mode Faults.
1.2. Byzantine Faults(拜占庭将军问题).
1.2.1. Fault Containment Region
- 系统可以分成多个Fault Containment Region.
- FCR外的错误不能导致其内部错误, 其内部错误也不能传播到外部.
- 实际中, FCR通常要求独立的处理器,存储器,IO,数据,以及电源.
1.2.2. Voting
- Voting is one method of using multiple FCRs, where a voter takes output from the FCRs and decides the correct output.
- 3 varieties:
- Exact: output values must match bit for bit.
- Approximate: values must be w/in a certain range of avg.
- Mechanical: system physically creates correct output. E.g.
- Each component provides a fraction of force needed to move output.
- A bad component will have its output overwhelmed by good
1.2.2.1. Voting Application
- Your messengers must be Byzantine Resilient also.
- Inputs, such as samples of sensor data, can also use a voter.
- Most aircraft provide redundant sensors.
- Transmission media can use voters and multiple connections.
- Voters are components! They must be extremely reliable or the system is pointless.
- Voting is often used to vote on the state of a component.
1.2.3. Triple Modular Redundancy
- Originated with Apollo.
- 3 systems operate on input. Majority value or average wins.
- The voter can optionally shutdown and reconfigure bad components.
- Created and used before Byzantine Generals’ paper, though it solves the same problem.
- Still widely in use today.
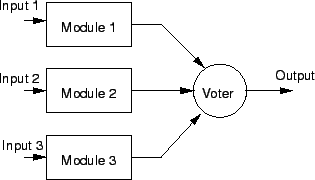
1.2.4. Dual Modular Redundancy/Replication
- This is not voting. Uses simpler hardware or software to reconcile outputs.
- Command / Monitor: command is primary CPU, monitor merely checks output of command.
- Primary / Backup: same as C/M, but backup computer can take over as primary.
- Hot Swap: backup always has same state as primary for instantaneous replacement.
1.2.5. Dual - Dual
- Two pairs of each processing component, both executing on all input.
- In each pair, both components send their output to simple hardware comparator. If it finds that output differs, switches over to other pair until first pair reconfigured / replaced.
- Used in lots of old interplanetary satellites.
1.2.6. Effects on Software
- Programs need to be written without knowledge of hardware resilience.
- Even operating systems are unaware of Byzantine Resilience, instead software just assumes that Byzantine Errors don’t happen.
- The hardware and software used to detect and isolate faults, mask errors, and reconfigure components are kept separate form any operational software.
- Simplifies code.
1.2.7. Error Detection
- If bitwise comparison with other components fails, declare failed component faulty. Most voting systems work this way.
- Thresholds / Reasonableness: check that component output is within a certain threshold.
- E.g. Asked to calculate time, returns 25 o’clock or STRAWBERRY
- Built-in Test: components check themselves for failures.
- Power-on BIT: checks itself at startup. Think POST.
- Continuous BIT: components check themselves periodically during slack time.
1.2.8. Component Synchronization
- For components to work together smoothly, their clocks must be synchronized.
- Clocks themselves must be Byzantine Resilient (to a certain degree).
- Surprise, redundancy needed.
- Voting used to determine the specific time.
- After time determined, push out to all Fault Containment Regions.
1.2.9. Reconfiguration
- Remove faulty component at the cost of redundancy.
- Replace faulty component with hot swap or spare, costs more in power or money.
- Fix state. E.g.
- Use voting to remake internal state of offending component
- Error Correcting Codes: use extra data in bits to find correct values
- Rollback: load state of system before crash. Usually impractical
- Transient Errors: vast majority of errors encountered do not repeat.
- Two ways of dealing with this:
- Keep rechecking value. If it persists, fault is permanent. Reconfigure something.
- Immediately reconfigure on failure, run BIT, and reintegrate if passes
1.2.10. Note on Buses
- The buses (such as communication or power, if you don’t have independent generators) must also be Byzantine Resilientish.
- Similar techniques would apply with small changes. E.g.
- Communication buses might have voting components located at each interface to an FCR, with multiple buses feeding in
- Backup buses in case one is damaged
- Etc..
1.3. Common Mode Failures(共因失效)
在上面的措施中, 拜占庭将军问题可以相对的得到解决, 剩下不能处理的问题还有共因失效.
共因失效会同时影响到多个Fault Containment Region.
Types:
- Transient (external): temporary result of environment (lightning)
- Permanent (external): constant interference from environment (flying in a tsunami)
- Intermittent (design): introduced during design of the system (can’t turn left in Illinois sometimes)
- Permanent (design): introduced during design of the system, doesn’t leave (can’t ever turn left in Illinois)
针对共因失效的问题, 可以这么解决:
- Fault Avoidance during design
- Fault Removal through testing, evaluation, fault insertion
- Fault Tolerance through exception handlers and program checkpointing / restarting
1.3.1. Fault Avoidance
- Don’t reinvent wheel.
- Problems arise because manufactures like to design own hardware
- Existing hardware has already been tested / verified in field
- COTS hardware offers a cheap alternative with lots of unofficial testing **
- Conform to existing standards for similar reasons
- Formal Methods
- The Space Shuttle takes this approach
- Design Diversity
- Run systems using different hardware / software designed by different teams
1.3.2. Fault Removal
- Basically means test the system rigorously to find problems.
- Fault Insertion: fake faults to make sure you system can handle them.
1.3.3. Fault Tolerance
- Watchdog Timers: task which occasionally runs and verifies system state.
- Could find an invalid PC, for example
- Hardware Exceptions: when invalid hardware operation found, throw and catch hardware exceptions.
- Runtime Checks: software exceptions, etc.
- Program Checkpointing: periodically save state, reload state when an error is found. Impractical often.
- Restarting: always an option.
1.4. Fault Tolerant Scheduler(容错调度)
- 假设我们的系统有一些重复的处理模块.
- 需求:
- 任务调度在模块间的调度需要满足timing requirements.
- 要提供相关容错的机制, 例如管理重复执行和任务成功检查
- Surprise, the solution involves executing tasks at different modules.
- 所有的任务重复和验证必须要满足deadline!
1.4.1. 硬件实现
- 每个处理模块都有一个用于同步和投票的冗余管理系统(RMS).
- RMS根据从重复任务中返回的数值以及整个处理模块的状态进行投票选择.
- 应用只会响应于所有RMS都投票的值.
- 如果RMS确定一个模块出现故障, 则该模块会受被降级, 并会得到新数据以进行恢复.
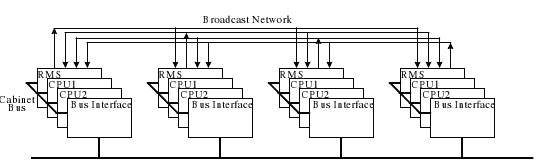
1.4.2. 软件实现
- 一个任务release后, 会模块间复制多份. 每当一个模块执行完任务, 其结果将移至投票队列.
- 在投票时间内(即任务release到deadline之间), voter会执行然后计算voting queue的结果. 投票消耗时间由所使用的算法确定
- 任何添加到voting queue但未由voter处理的任务必须在下次被处理.
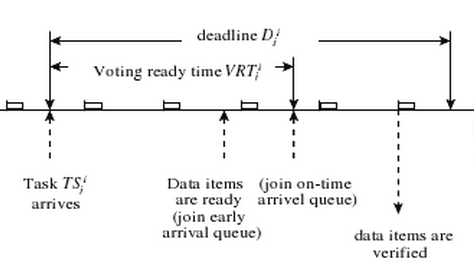
1.5. 相关历史
- 最早是NASA和一些航空电子设备制造商开始关心故障避免.
- Apollo had a computer with rigorously verified code. No permanent failure was ever recorded.
- 使用Triple Modular Redundant和Dual-Dual的系统在70年代早期开始出现
- Exact consensus was used for fault detection / isolation
- 第一个相关商业案例出现在大型喷气式飞机的自动着陆功能中.
- 747 used TMR, Lockheed L-1011 Dual-Dual
- Dual-Dual和TMR被设计来防止拜占庭故障, 虽然这个时候其理论尚未被提出.
- 后来对拜占庭容错的研究为这些设计提供了理论依据.
- 这之后, 最主要导致出错的原因变成了Common-Mode Failures.
- 航天飞机设计上必须能够在一次出错后还能完成任务, 在两次出错之后还能安全降落.
- 因此使用了4个独立的计算系统, 每个都是一个FCR.
- 同时还装备了一个简单的备份系统, 如果需要可以完成降落的任务.
- 这算是早期的Common Mode Failures保护措施, 虽然设计上没有明确出来
2. 相关案例
2.1. Waymo

上面是Waymo Safety report里的Safety-Critical Systems描述.
备用运算, 备用制动, 备用转向, 备用电源, 备用碰撞, 冗余惯性测量.
2.2. Elektrobit
Challenges and current solutions for safe and secure connected vehicles
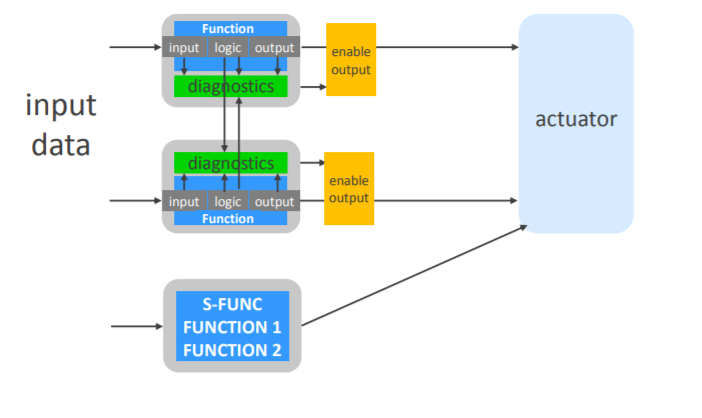
这个文档里不是讲自动驾驶的, 主要是汽车ECU相关的safety architecture.
大致也可以看到相关思路也是符合上述理论的.
Designing a software framework for automated driving
2.3. Audi A8 zFAS
zFAS有4个核心元件, 包括Mobileye的EyeQ3, 负责交通信号识别, 行人检测, 碰撞报警, 光线探测和车道线识别.英伟达的K1负责驾驶员状态检测, 360度全景.英特尔(Altera)的Cyclone V负责目标识别融合, 地图融合, 自动泊车, 预刹车, 激光雷达传感器数据处理.英飞凌的Aurix TC297T负责监测系统运行状态, 使整个系统达到ASIL-D的标准, 同时还负责矩阵大灯

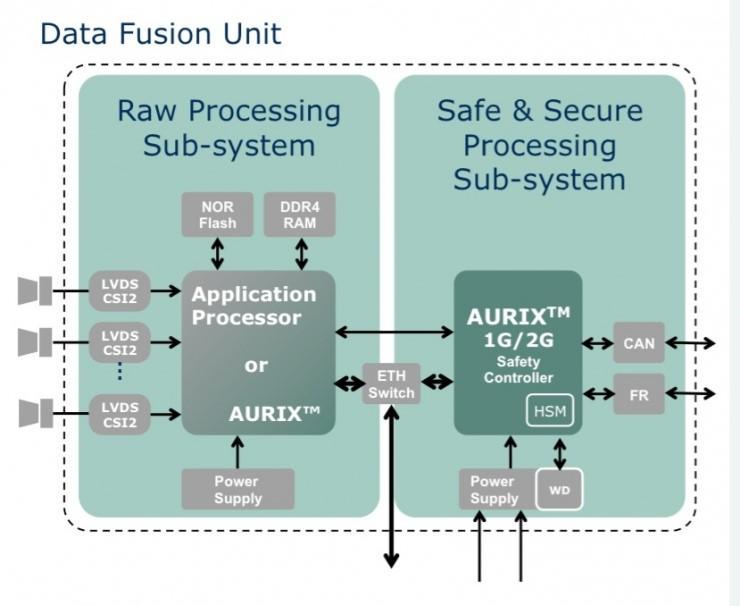
这里值得一提的是, zFAS上各处理器之间的bus和middleware使用的TTTech的技术, 这也是一个很关键的安全设计.
3. 无人车
基于上述背景知识, 来设想一下如何为无人车设计容错架构.
3.1. 思路
按照功能安全的分析方法, 思路应该是:
- 项目定义
- 危险分析和风险评估
- 功能安全概念设计
- 系统开发
- 安全确认
这里就随意点, 按照如下的思路来:
- 列出可能的 Byzantine Faults 和 Common Mode Faults
- 解决思路
- 输出结构
- 具体实现
3.1.1. 不同点
对航空器设计来说, 其所关注的是针对由于软硬件系统”故障失效”而导致的安全风险.但对运行着自动驾驶软件的无人车来说, 安全问题并不一定仅仅由于系统”故障失效”引起.更多的场景下, 可能是因为自身系统设计上的limitation导致的安全风险.
因此这里需要再加入针对performance limitation的考虑.当然重点不放在如何找到以及改善performance limitation, 这个是扩大到整体系统安全范畴了. 主要关注的是, 针对环境超出performance limitation后的容错处理.
3.2. Faults
底盘域不考虑, 假设已符合标准.
硬件:
- 电源故障
- 总线(CAN/ETH)故障
- 传感器故障
- 计算平台故障
- 元器件故障
- 粒子翻转
- 移动网络故障
- ……
按模块分的软件故障(以apollo为例):
- Sensor software Faults
- Planning Faults
- Perception Faults
- Localization Faults
- Map Faults
- Control Faults
- System software Faults
模块是有上下游的, 因此对于下游的模块, 更需要注意.
软件故障会引起的现象:
- 进入循环
- 挂起
- 崩溃
- 性能下降
- 结果不正确
3.3. 解决方法
解决手段:
- 多样
- 冗余
- 监控
严谨的流程中, 使用何种解决手段, 使用到什么程度, 是根据失效概率和安全等级来决定的. 不过作为单纯的YY, 不可能做到这种程度, 因此这里只简单使用下列规则.
选择双重冗余与三重冗余与多样化冗余的规则.
- 如果一个模块, 在其出错的时候, 基本都能检测出来(error detection), 那就使用双重冗余.
- 如果模块的错误有很大的概率无法被检测, 则使用三重冗余.
- 如果不同类型的模块可以互补替代, 则优先使用多样化冗余.
再增加一个不使用冗余的规则.
- 出错可以被检测, 同时短期内不会对驾驶造成影响.
3.4. 结构
3.4.1. 系统

3.4.2. 硬件容器

3.4.2.1. 电源
电源上的冗余是底盘平台设计要综合考虑的事情, 所以图中就不再画出.
假设底盘已经有12v主电源, 12v备用电池的概念, 支撑传感器域和计算域的电源.
对计算平台的部分来说, 其电压容限比较小, 最常见的共因失效就是电源.
因此对计算平台ABC来说, 必须板载独立的PMIC或者电源隔离, 同时可以在板级采用不同的设计来增加多样性.
3.4.2.2. 总线
图上没有解释总线的设计.
这是因为总线有很多成熟的技术方案, 可靠性也比较好, 都会有信息冗余/硬件冗余的支持.
对无人车来说, 车载以太网是比较好的选择.
现有车载以太网方案里很多都是针对娱乐/ADAS系统设计的, 可能不太合适无人车.
适合自动驾驶设计的, 可以看Time-Triggered Ethernet.
3.4.2.3. 传感器
3.4.2.4. imu
imu失效会快速导致无人车定位的误差, 引起重大的安全风险, 所以必须采用硬件冗余.
imu可以用confidence决定数据采用, 因此采用双冗余的方式即可.
参考: 无人机IMU三冗余
3.4.2.5. 雷达/摄像头
障碍物识别相关的传感器以多样化互补为主, 这里的冗余能力主要取决于算法融合的效果.
不过除了障碍物识别, 一些边角的感知需求, 比如说红绿灯识别/信号灯识别/车道线识别, 是无法基于雷达的数据获取的,
则有必要考虑在摄像头部分做硬件冗余.
3.4.2.6. 其他
GPS和时间同步等并不影响短期内的驾驶行为, 出错后车辆可以完成自主停车操作, 因此不做备份.
如果GPS失效几率会比较大, 影响到无人车运行效率, 则再考虑添加冗余.
3.4.2.7. 计算系统
3.4.2.8. 备份安全平台
物理隔离的备份安全平台, 在百度apollo和waymo的相关透露信息中都有提到.备份安全平台在硬件设计上主要是能采用更可靠的硬件/驱动程序, 使用已经被广泛验证的平台和技术, 不像计算单元那样受限制于计算能力. 如此, 为整体带来Design Diversity.
3.4.2.9. 计算平台
按经验来说, 计算平台硬件出现失效的概率应该是不大的, 做双冗余即可. 或者不做冗余关系也不大, 如果有备份安全平台的存在.
此处做三冗余, 主要出于软件上的考虑.
3.4.2.10. Control ECUs
以百度apollo为例, 其Trajectory Control, Longitudinal/Lateral Control是直接在计算平台内做的.此处分到ECU上, 主要是看所有车厂放出的架构里, Control都是在ECU上做的, 比如说BMW.
当然他们这么做, 多半是为了直接复用ADAS上自适应巡航, 自动泊车的模块.
我们这里这样选择, 主要是出于Diversity, 成熟设计稳定性, share ability的原故.
3.4.2.11. 车联网
网络的风险主要在于空口问题引起的延迟/断网, 因此采用不同网络并存.
网络虽然不是自动驾驶所必须的部分, 但是出于监控的需要, 硬件上也有必要使用双冗余.
IMO, 网络是非常不稳定的因素, 任何设计都不能信任网络, 不能做为保底措施.
3.4.3. 软件组件

3.4.3.1. Control ECUs
都是成熟设计, 省略……
3.4.3.2. 计算平台
如上设计, 从容错的角度上讲.
- 解决因为程序异常, 包括崩溃/挂起/循环, 引起的Byzantine Faults
- 减少因为使用非实时系统与应用可能出现的延迟/性能下降, 引起的Byzantine Faults
- 可以布置多样性的算法策略(也可以算是同一代码的ABC版本), 从design上减少共因失效.
从软件角度上讲.
- 更多的算力, 改善算法的Performance Limitation. 以Cruise的自动驾驶为例, 使用了5个激光雷达, 16个摄像头, 20多个毫米波雷达. 数据量不是单计算平台可以承担的.
- 提供版本ABTEST的能力
如何基于决策和路径规划的输出来做Vote的实现, 没想明白. 可以就只是简单的根据监控的结果, 对失效平台传过来的数据做丢弃.
另外, 在哪里做vote也是个没有考虑清楚的问题. 可能考虑分布式投票, 放置于计算平台之上(采用中断的实现方式, 在实时Linux上的延迟应该是1ms内的).
3.4.3.3. 备份安全平台
备份安全平台是容错设计的核心部分.
这里就直接放apollo的图.
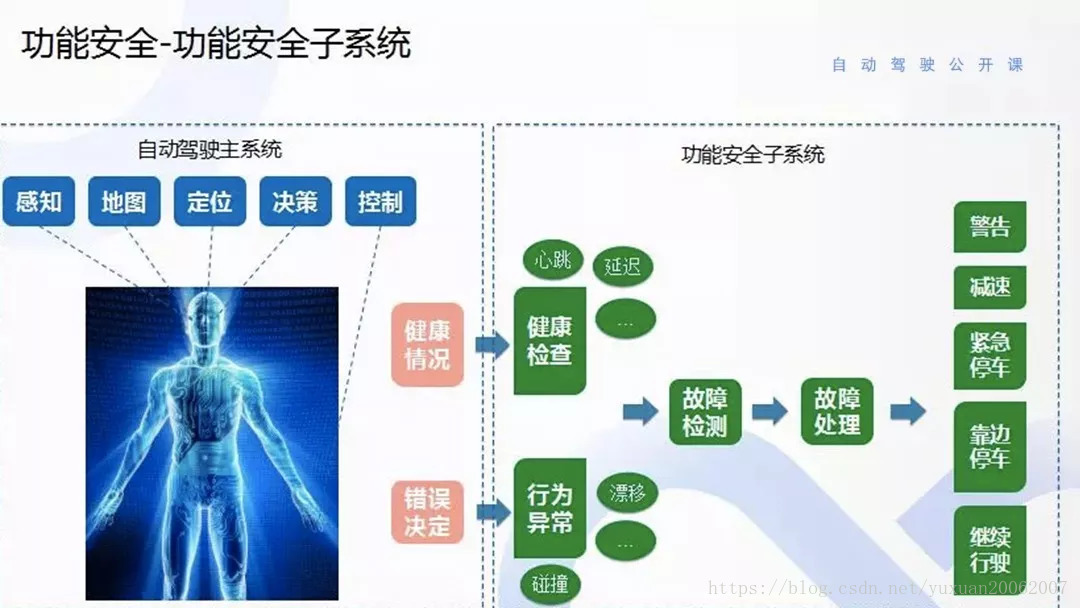
这是功能安全的主系统思路。把系统比成一个人,感知是大脑,控制是手和脚。它的心脏有反应,就无法驾驶车辆,有安全风险。反应慢,也有可能造成安全风险。假如现在这个人是健康的,但也有可能错误决定造成安全隐患,比如突然右转。处理方法就是做故障检测,故障检测之后会进行故障处理,分等级处理,第一个等级警告。然后,就是减速,系统延迟比较大时,只能降速行使,因为高速会发生危险。之后是停车,比如传感器失效,紧急停车。否能够靠边停车是由发生的故障决定,比如感知系统失效就不能前后靠边停车。
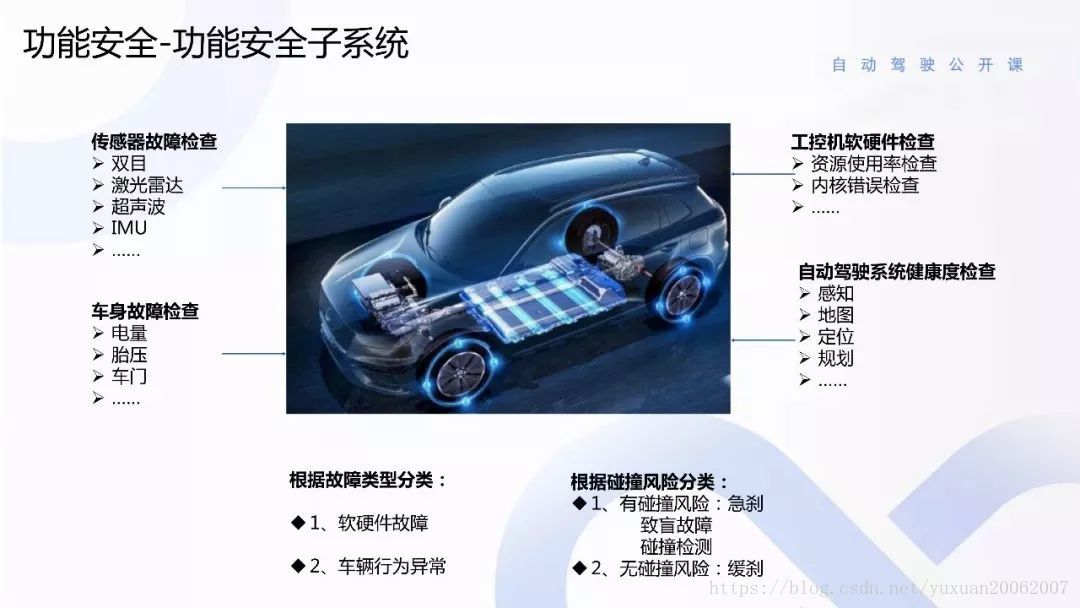
还有主系统坏了后有一个备用系统进行巡视。根据故障可以进行分类,分成人的故障和车的行为故障。如果车软硬件发生故障,相当于车的健康率发生故障,就不能行使。另外,根据故障分成几类,有碰撞风险是急刹,导盲故障。还有是碰撞检测,这种可以根据障碍物进行缓刹和非急刹的策略。还有一种是无碰撞风险障碍。
还有waymo的描述.
含碰撞检测及碰撞规避系统在内的多个备用系统可持续扫描车辆前后的物体,包括:行人、骑行者及其它车辆。若主系统未探查到行驶路径中的目标物(极少数情况),这类备用系统可控制车辆,逐步减速直至安全停靠。
熔断防撞, 是设计上避免严重后果的最后防线.
在实现逻辑上和计算平台Guardian基本不会有太大区别, 也是基于RSS/安全距离来做.只是鉴于备份安全平台的设计原则和计算能力, 数据来源一般都是用2D激光/超声波这种false/true数据, 或者毫米波雷达/MobileEye这种直接输出tracklet数据, 所以效果必然比主系统差.主要是覆盖万一情况.
3.4.4. Performance Limitation
如上, 一直讲的都是容错,除了熔断防撞/Guardian算是针对Performance Limitation的防线. 但是熔断防撞/Guardian逻辑本身也只是简化版的算法, 一样有他自己的限制以及限制于传感器.
自动驾驶算法现阶段的Performance Limitation有多大, 都应该清楚.
特别是高速场景下, false/true逻辑覆盖不到, 只依赖感知结果会导致不安全区域巨大.
IMO, 如果要无人化运营, 请合理规划最高速度, 明确安全区域
针对Performance Limitation, 目前想到的:
- 完善交互设计, 依靠安全员的判断
- 不造成严重后果, 限速/车外气囊等等
3.6. 分析设计
对上述设计基于失效概率/安全等级进行分析
省略……
3.7. 其他
加入的这些结构会增加成本, 增加复杂度, 影响驾驶效率等等.
最终还是要靠合理的论证和测试, 确定如何平衡安全与成本与效率.