无人车实时优化-CPU分配与任务调度探讨
-
date_range infosort

1. 背景
1.1. Task
In computing, a task is a unit of execution or a unit of work. The term is ambiguous; precise alternative terms include process, light-weight process, thread (for execution), step, request, or query (for work). In the adjacent diagram, there are queues of incoming work to do and outgoing completed work, and a thread pool of threads to perform this work. Either the work units themselves or the threads that perform the work can be referred to as "tasks", and these can be referred to respectively as requests/responses/threads, incoming tasks/completed tasks/threads (as illustrated), or requests/responses/tasks.

1.1.1. Task Triggers
触发是说当一个标准满足时,任务开始执行.
- 一般来说, 触发原因分为下面两种:
- event-based
- time-based
- 一个任务可以有很多触发原因, 不过在实际编程场景下倾向用单触发.
- 不负责任的说, 公式里带t的用时间触发
- PID: ${\displaystyle u(t)=K_{\text{p}}e(t)+K_{\text{i}}\int {0}^{t}e(t’)\,dt’+K{\text{d}}{\frac {de(t)}{dt}},}$
- Kalman filter: ${\displaystyle \mathbf {x} _{t}=\mathbf {F} _{t}\mathbf {x} _{t-1}+\mathbf {B} _{t}\mathbf {u} _{t}+\mathbf {w} _{t}}$
- 反例:
- imu积分求位移, 最好由imu sensor-data event触发
- 所以修正: 两者都可以用, 随你喜欢……
- 反例:
- 优先event-based, 可以减少latency
- 使用time-based的几种情况
- latency不敏感, 无关紧要的链路
- 输入事件的频率的达不到要求或者不稳定, 需要插值的场合(比如说各种control)
- 如果频率不够高, 会带来很大的延迟, 比如20hz就是50ms的链路延迟.
- 如果上下游都用到了插值, 尽量合并
- 无法决定合适的输入事件
- 自动驾驶上规划决策是个例子, 一般都是定时器触发为一个frame
- time-based的任务适合deadline调度
- event-based的任务适合优先级抢占式调度
延迟最优化的情况下, 程序应当全部是event-based的task, 从data src开始向下一直到最下的sink.
音视频的开发就是个延迟敏感的典型, 所以我们可以看到一些音视频开发框架采用的pipeline概念.
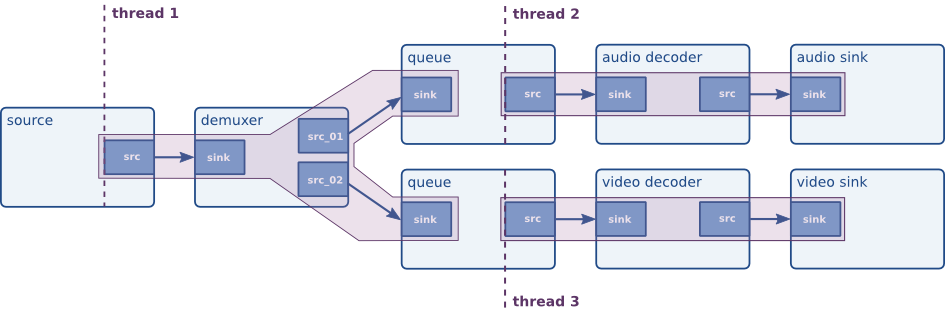
2. Apollo Cyber
这里直接把关于调度的ppt截取出来
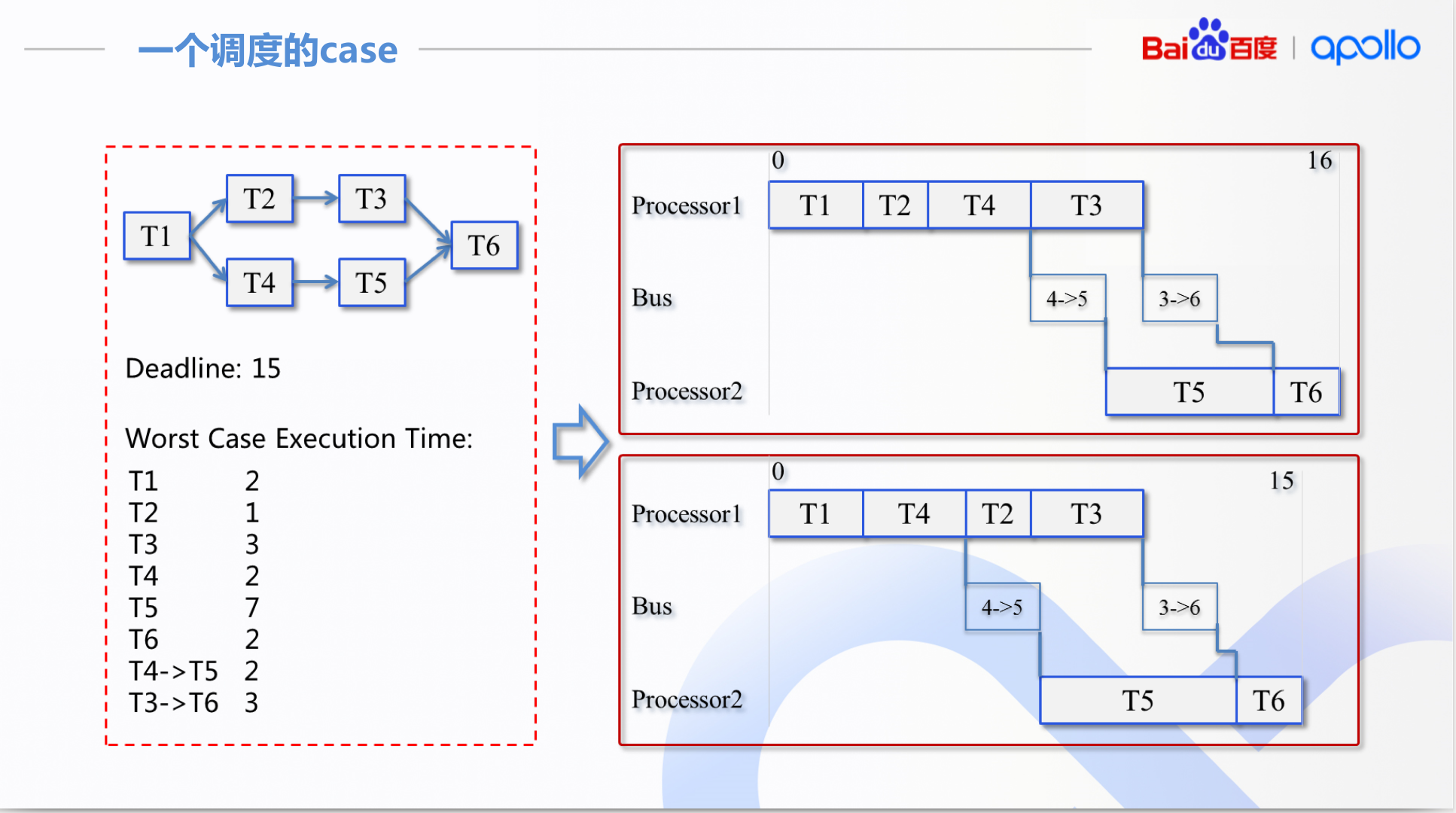
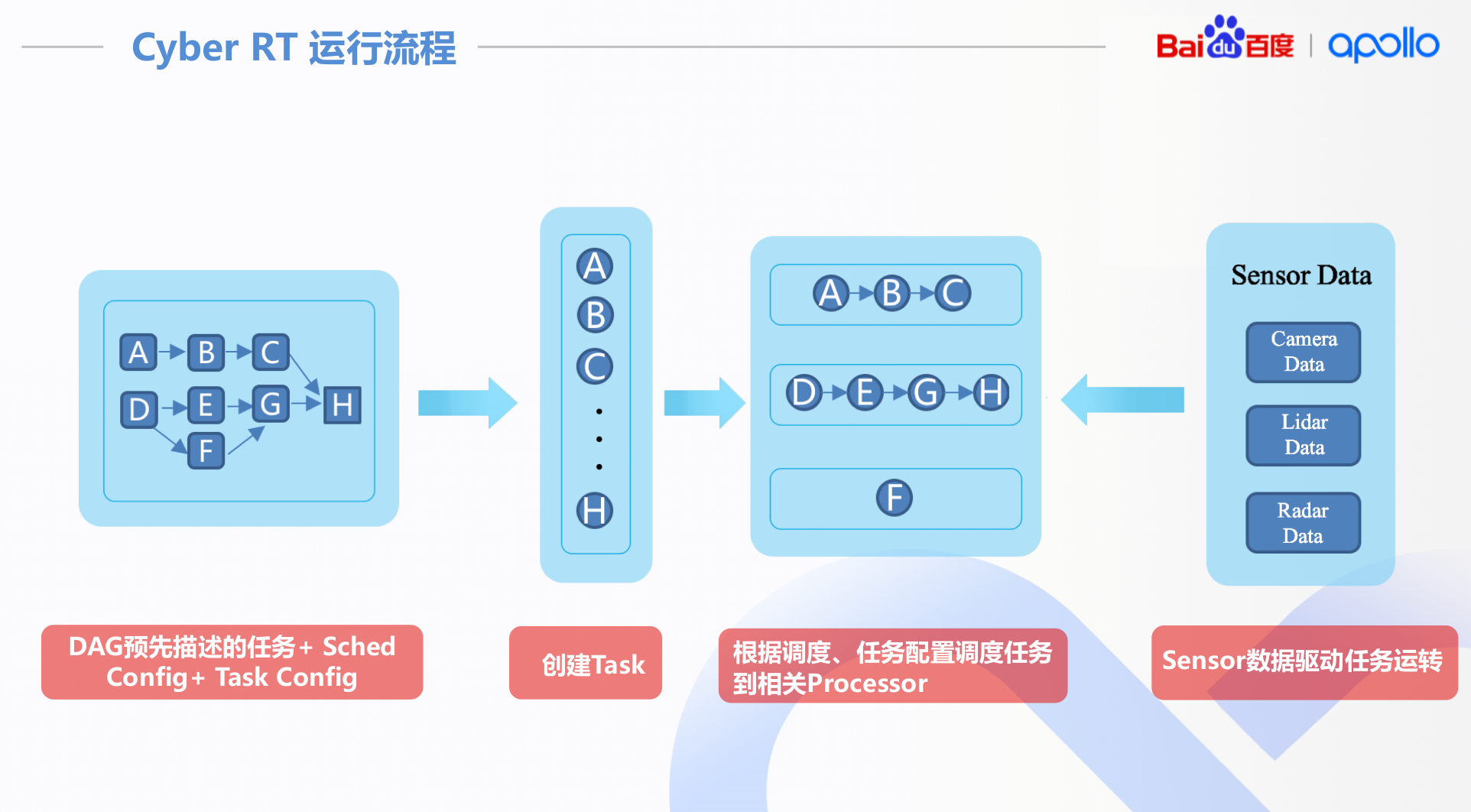
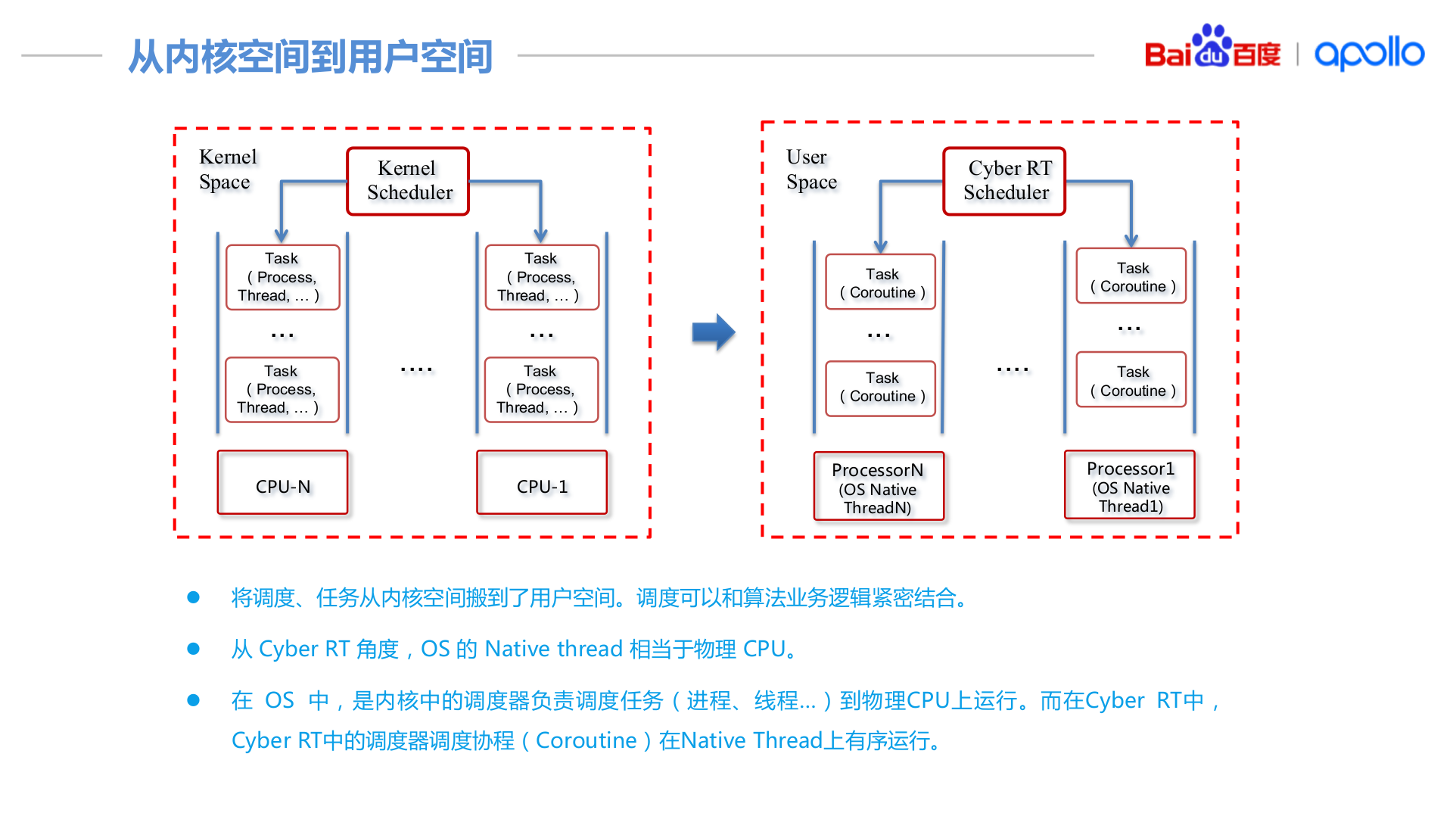
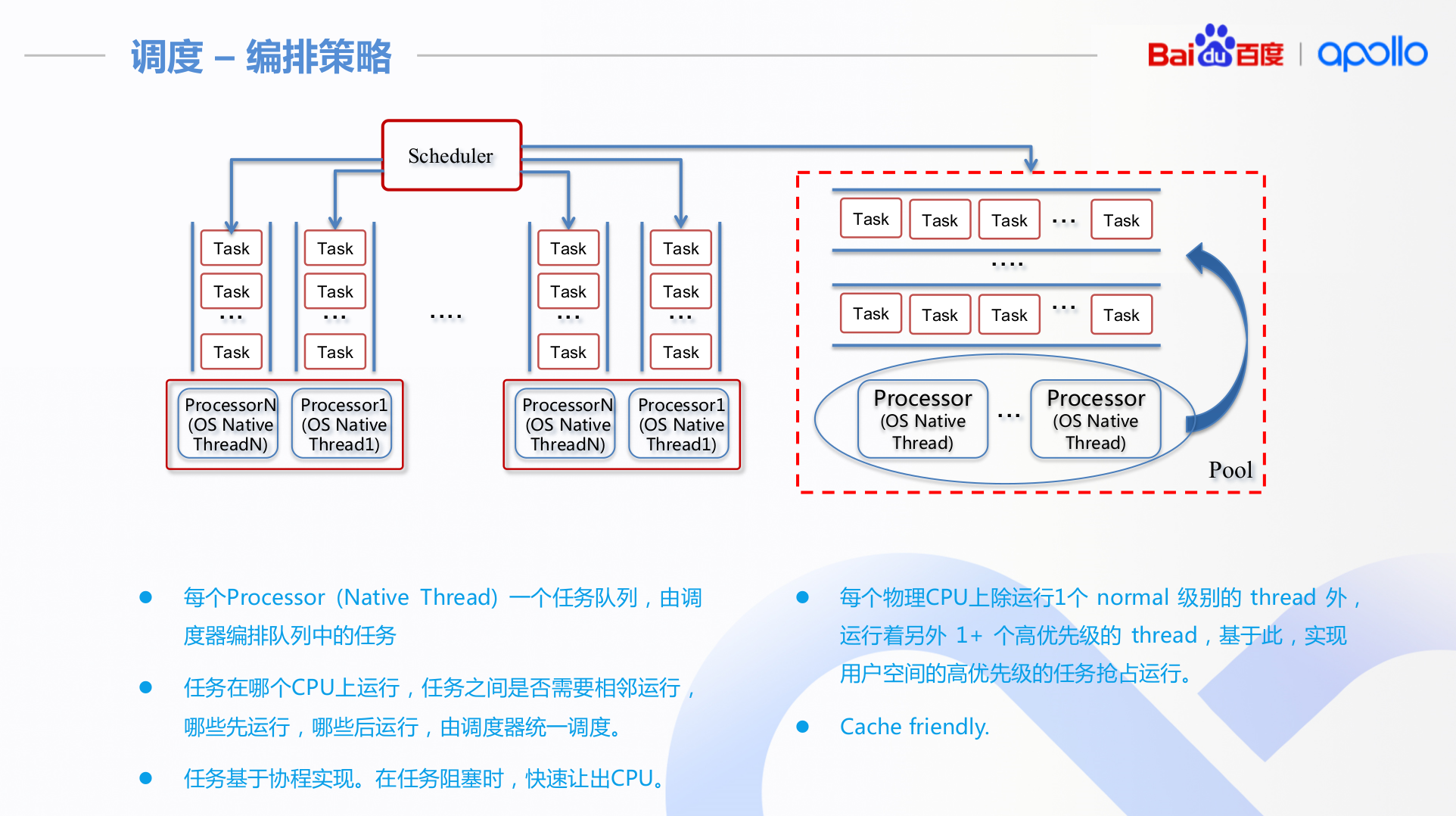
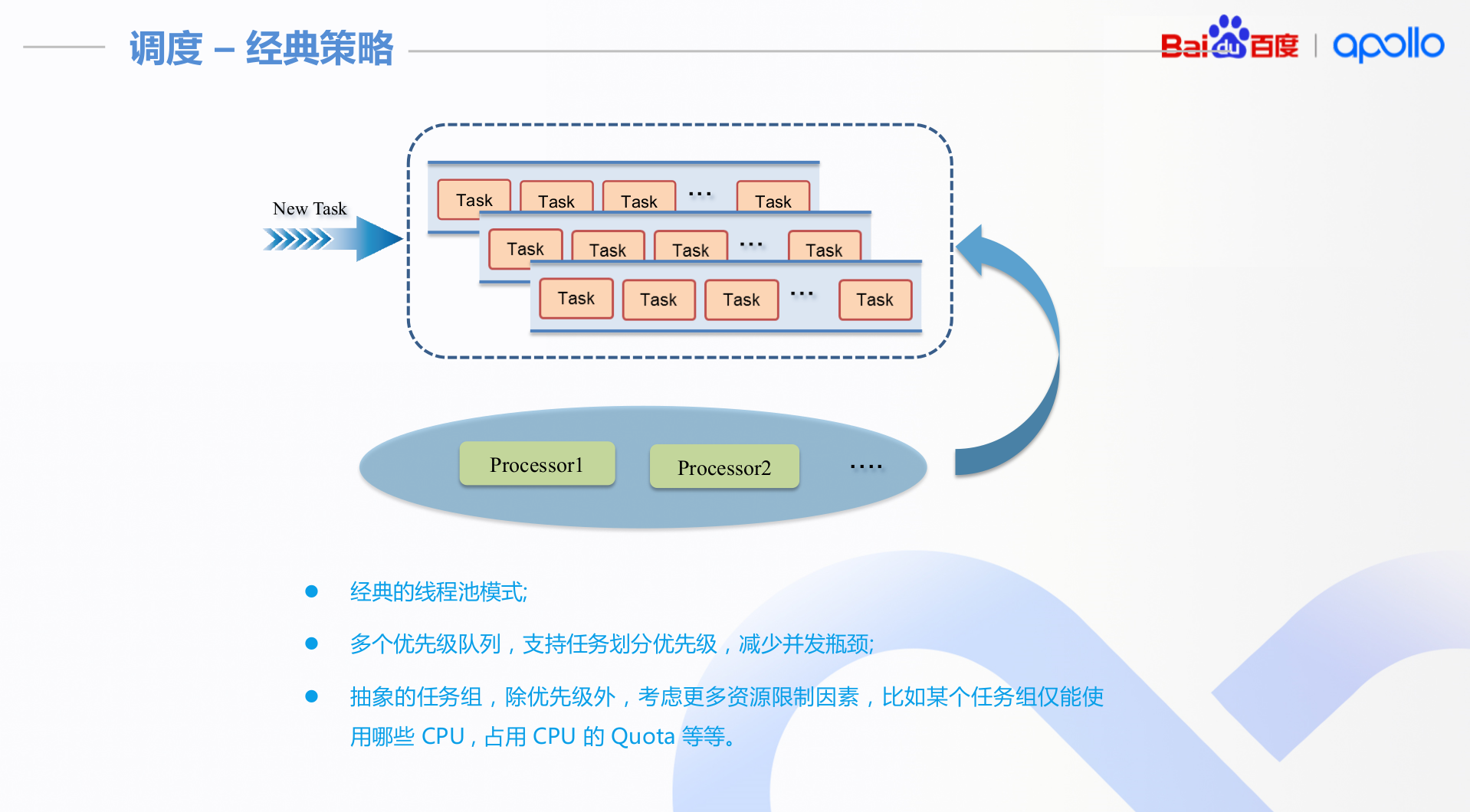
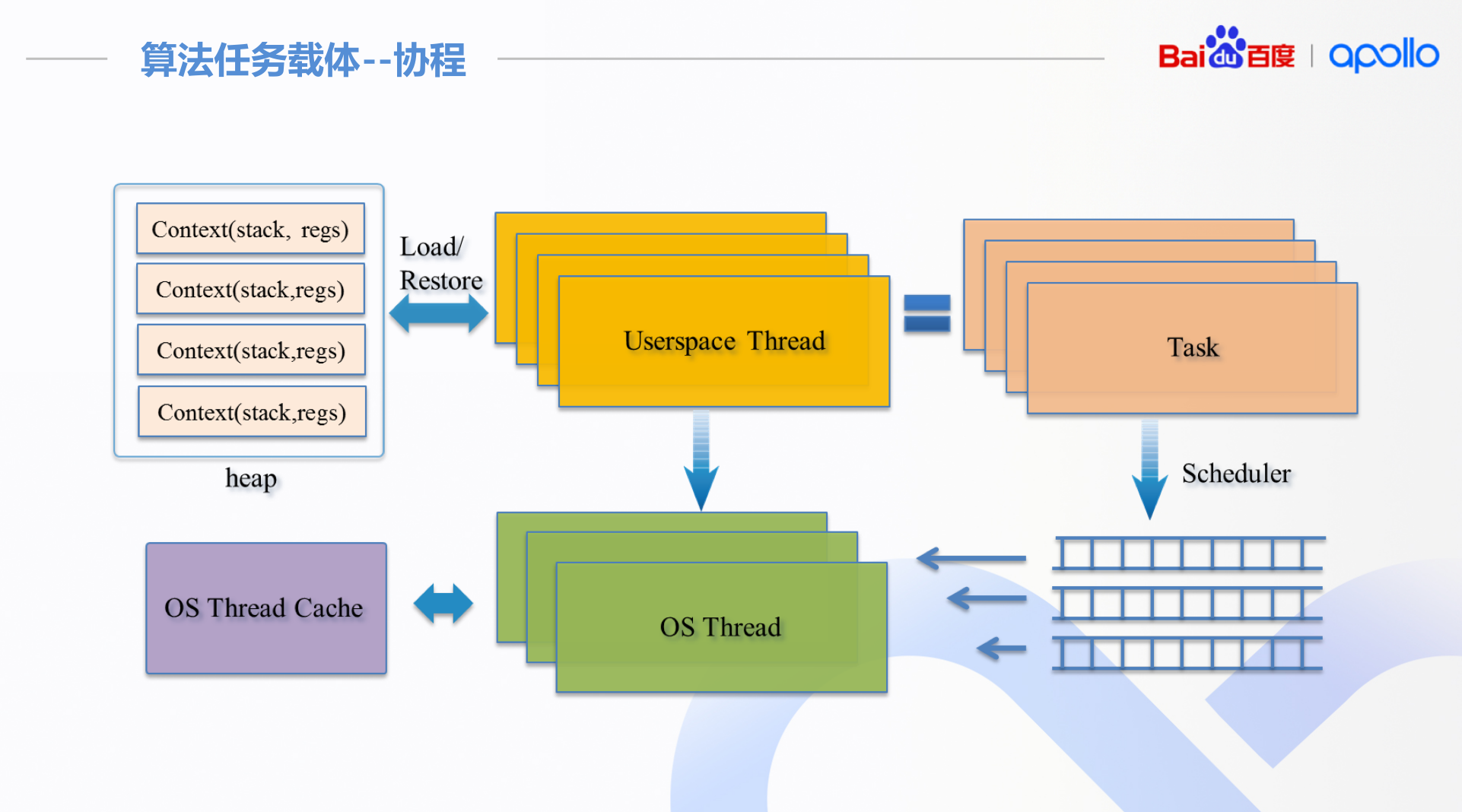
apollo的做法归纳起来就是:
- 协程: 用户层对task进行调度
- dag: 基于dag的task连接关系确认, 用于调度优化
- 调度策略: 编排策略和经典策略
一些blog:
2.1. 实际使用
apollo这块具体的使用主要是通过配置文件, 所以就通过配置文件分析具体怎么使用.
2.1.1. DAG
module_config {
module_library : "/apollo/bazel-bin/modules/canbus/libcanbus.so"
timer_components {
class_name : "CanbusComponent"
config {
name: "canbus"
config_file_path: "/apollo/modules/canbus/conf/canbus_conf.pb.txt"
flag_file_path: "/apollo/modules/canbus/conf/canbus.conf"
interval: 10
}
}
}
如上是canbus的dag, 表示加载一个timer_components, 以10ms的速度调用.
从task的视角来看, 就是增加了一个叫做canbus的timer task.
此外在代码里, canbus会创建一些收发消息的reader, 也会变成task.
module_config {
module_library : "/apollo/bazel-bin/modules/planning/libplanning_component.so"
components {
class_name : "PlanningComponent"
config {
name: "planning"
flag_file_path: "/apollo/modules/planning/conf/planning.conf"
readers: [
{
channel: "/apollo/prediction"
},
{
channel: "/apollo/canbus/chassis"
qos_profile: {
depth : 15
}
pending_queue_size: 50
},
{
channel: "/apollo/localization/pose"
qos_profile: {
depth : 15
}
pending_queue_size: 50
}
]
}
}
}
从task的视角来看, 这里增加了一个叫做planning的task.
此外, 会根据dag直接创建3个收消息的reader task.
2.1.2. 调度配置文件
SchedulerClassic
Choreography Classic就是根據用家給的scheduler conf去給每個task priority,然後就按conf中預先設定的priority去做。還支持把Processor做分組,某不同range的Processor負責不同的種類的任務。
SchedulerClassic中的ClassicContext是用static變量去放CRoutine的,CRoutine不能保證自己被該組中的那一個Processor執行。而每個ClassicContext都有一個group_name_,那Processor在拿Task時只會拿到該group的Task。
SchedulerChoreography
SchedulerChoreography跟SchedulerClassic沒有差很大,它是在支持SchedulerClassic的前題下(但不支持Processor分組),把一部份的processor留出來,容許你指定每個task用當中那一個processor。所以被特別留出來的processor,各有一個自己的context,不跟其他processor共用,確保該processor只會處理指定的Task
传统调度的配置文件:
PS: control_/apollo/planning表示controlcomponent收/apollo/planning消息的reader task.
scheduler_conf {
policy: "classic"
classic_conf {
groups: [
{
name: "control"
processor_num: 8
affinity: "range"
cpuset: "8-15"
processor_policy: "SCHED_OTHER"
processor_prio: 0
tasks: [
{
name: "control_/apollo/planning"
prio: 10
},
{
name: "canbus_/apollo/control"
prio: 11
}
]
}
]
}
}
翻译过来就是, 建立一个processor(thread)为8的pool, processors间使用的是SCHED_OTHER调度策略, 就是CFS.
control_/apollo/planning和canbus_/apollo/control任务设置了优先级, 比其他任务的默认0优先级要高.
task按照classic的方法调度, 背后的实现是multi prioty queue, 调度任务的时候, 从优先级高的queue开始找到需要执行的程序.
编排策略的配置文件:
scheduler_conf {
policy: "choreography"
choreography_conf {
choreography_processor_num: 2
choreography_affinity: "range"
choreography_cpuset: "8-12"
choreography_processor_policy: "SCHED_FIFO"
pool_processor_num: 2
pool_affinity: "range"
pool_cpuset: "12-15"
pool_processor_policy: "SCHED_OTHER"
tasks: [
{
name: "control_/apollo/planning"
processor: 0
},
{
name: "canbus_/apollo/control"
processor: 0
prio: 2
}
{
name: "guardian"
processor: 1
},
]
}
}
翻译过来就是, 建立一个processor(thread)为2的group, 使用的SCHED_FIFO的调度策略, 就是实时调度, 可以抢占.
control_/apollo/planning和canbus_/apollo/control任务专门绑定到processor 0上, canbus的优先级为2, 比默认1要高.
task按照choreography的方法调度: processor 0只给两个task, canbus用完了给control. guardian在processor 1上, 是实时进程, 只要guardian有需要, 可以随时抢占processor 0的物理cpu.
group里的其余任务默认优先级配置为0, 放入一个processor(thread)为2的pool, 继续按传统方法调度.
2.2. 总结
ppt里写的很好, 但是apollo实际开源出来的并没什么内容.
原以为有根据DAG里的上下游来优化编排/调度策略, 但就代码来看, 是没有这样的逻辑.
总结起来:
- 调度规则配置化.
- 任务协程化.
3. 探讨
综上的一些技巧, 这里设想针对自动驾驶程序设计cpu分配和任务调度.
3.1. CPU分配
从cpu的角度上, 主要需要做的是按Group划分Cpuset资源.
不建议使用限制时间片的方式, 隔离的不够彻底.
3.2. 任务调度
cpu按Group划分完后, 就是每个Group里单独做task scheduler.
简单的scheduler做法, 就是使用thread pool + kernel scheduler(优先级/cfs)的方式.
就自动驾驶程序而言, 大体上可以:
- 感知+预测+定位+决策+规划的compute部分
- 重要的节点绑定CPU, 核心task和部分iotask使用优先级抢占调度
- 其余节点CFS分配资源, 可划分优先级
- 控制+防撞+底盘组成的control部分
- 全部绑定CPU, 核心task和iotask使用优先级抢占调度
- 硬件驱动部分
- 重要的节点绑定CPU, 核心task使用优先级抢占调度
- 其余节点CFS分配资源, 可划分优先级
就ROS节点内部来说:
- 处理核心逻辑的proc task为最高优先级
- 一个程序在设计上应该只有一个关键的proc task!
- 处理io的thread优先级根据需要配置
- 比如说控制到防撞到底盘的io thread优先级要高
- 创建thread的接口要收拢
- 其余thread默认cfs分享cpu
就tuning配置来说:
- 以task为单位提供执行timeline/占用率等perf能力
- 以此衡量调度配置的合理性, 主要的指标:
- deadline
- 以此衡量调度配置的合理性, 主要的指标:
- iotask的调度配置合理性通过qos判断, 主要的指标:
- deadline
我觉得这种做法做到就很不错了, 像apollo那样的协程优化是没必要的.
3.3. 作用
apollo的ppt展示其调度优化的意义是(虽然实际开源代码里没有):
- 减少链路的延迟
对无人车做CPU分配与任务调度, 还有一个主要意义:
- 保证task/io调用时间可控, 从而系统延迟可控
IMO, 自动驾驶程序而言, “确定性”比”延迟”关键.
先可控, 再谈减少.